데이터에서 의미를 찾고 싶으면
전체를 통계내는 것 보다 특정 그룹을 뽑아서 통계를 내는게 훨씬 의미찾기 쉽다고 했습니다.
특정 그룹을 뽑고 싶으면 WHERE 써서 필터링하면 되는데
그룹 뽑을게 많다면 GROUP BY 문법 사용하면 편리할 수 있습니다.
GROUP BY
SELECT 고객등급 FROM card
GROUP BY 고객등급 저번시간 card 테이블에서 GROUP BY 문법을 써봅시다.
1. SELECT FROM 뒤에 GROUP BY 컬럼명을 붙일 수 있는데
2. 그럼 그 컬럼에 있는 카테고리끼리 그룹지어서 보여줍니다.

▲ 실행해보니까 진짜 카테고리끼리 그룹지어줌
(실은 DISTINCT 동작방식이랑 유사합니다.)
근데 그룹만 지으면 아무 쓸모가 없습니다.
GROUP BY는 전에 했던 MIN MAX COUNT SUM AVG 함수와 함께 이용하는 경우가 매우 많습니다.
그럼 각각의 카테고리마다 MIN MAX COUNT SUM AVG 값을 출력해볼 수 있음

SELECT 고객등급, COUNT(고객명) FROM card
GROUP BY 고객등급 COUNT(고객명) 컬럼을 추가하면
각 카테고리마다 COUNT(고객명)을 출력해줍니다.

SELECT 고객등급, AVG(사용금액) FROM card
GROUP BY 고객등급 AVG(사용금액) 컬럼을 추가하면
각 카테고리마다 AVG(사용금액) 을 출력해줍니다.
오늘의 결론은 카테고리마다 통계를 내보고 싶으면 GROUP BY 쓰면 됩니다.
GROUP BY는 category column에 주로 사용함
테이블을 관찰하다보면 category column들이 있습니다.

▲ 여기선 '고객등급' 컬럼

▲ 저번 이마트 상품 테이블에선 '카테고리' 컬럼
이런걸 category column이라고 합니다.
여러 항목 중 어떤 항목에 속하는지 분류하기 위해 만든 컬럼입니다.

▲ 물론 가격이나 재고 컬럼도 category column 이라고 볼 수 있습니다.
중복된 데이터들이 많이 보이면 그것도 일종의 카테고리라고 생각할 수 있으니까요.
그리고 category column 컬럼들에 주로 GROUP BY 문법을 사용해야 의미있는 결과가 나옵니다.
중복데이터들이 많아야 그룹을 지을 수 있으니까요.
GROUP BY 한 결과도 필터링 가능
GROUP BY로 그룹지어서 출력한 것도 너무 행이 많으면 필터링할 수 있는데
뒤에 HAVING 조건문 쓰면 됩니다.
GROUP BY 뒤에만 붙일 수 있는 특별한 조건문입니다.
SELECT 고객등급, COUNT(고객명) FROM card
GROUP BY 고객등급
HAVING 고객등급 = 'vip' 이러면 아까 출력한 3개의 행 중에 고객등급 = 'vip'인 1개의 행만 필터링해줍니다.
HAVING vs WHERE
HAVING은 용도가 WHERE과 비슷합니다. 둘 다 조건식 입력하는 문법입니다.
-HAVING은 GROUP BY 결과를 필터링하고 싶을 때 씁니다.
그래서 GROUP BY 뒤에만 붙일 수 있습니다.
- WHERE는 테이블 전체 데이터 출력시 필터링하고 싶을 때 쓰면 됩니다.
그래서 SELECT FROM 뒤에만 붙일 수 있습니다.
SELECT 고객등급, COUNT(고객명) FROM card
WHERE 연체횟수 = 0
GROUP BY 고객등급
HAVING 고객등급 = 'vip'
그래서 학원들 보면
SELECT / FROM / WHERE / GROUP BY / HAVING / ORDER BY 순으로 작성한다고 외우라고 시키는데
근데 각각 문법의 용도만 잘 기억해두면 자연스럽게 사용할 수 있기 때문에 순서 외우고 그럴 필요없습니다.
문법의 용도만 잘 기억해둡시다.
오늘의 숙제 :
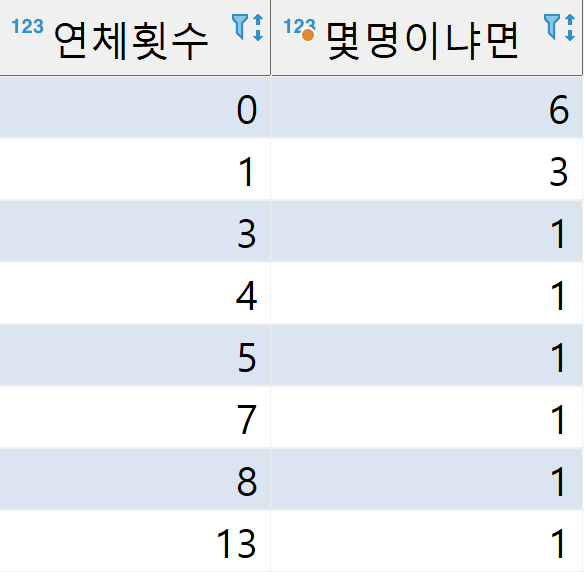
Q1. 위 사진처럼 card 테이블에서 연체횟수마다 몇명이 있는지 출력해봅시다.
보기좋게 연체횟수 기준으로 정렬도 합시다.
SELECT 연체횟수, COUNT(*) AS 몇명이냐면 FROM card
GROUP BY 연체횟수
ORDER BY 연체횟수

Q2. Q1에서 출력한 결과가 너무 길어서 몇명이냐면 컬럼의 값이 1명인 행은 안보이게 필터링해봅시다.
SELECT 연체횟수, COUNT(*) AS 몇명이냐면 FROM card
GROUP BY 연체횟수
HAVING 몇명이냐면 != 1
ORDER BY 연체횟수 AS키워드로 작명한 컬럼도 필터링가능합니다.
내가 그걸 어떻게 아냐고요?
약간의 모험정신을 길러보거나 구글의 도움을 받는게 좋습니다.

Q3. 위 사진처럼 card 테이블에서 회원등급별로 최대사용금액과 최소사용금액이 몇배나 차이나는지 구해봅시다.
GROUP BY는 선택사항일 뿐 안써도 됩니다. 35.76 / 18.13 / 30.4 저것들만 잘 출력되면 됩니다.
SELECT max(사용금액), min(사용금액), max(사용금액) / min(사용금액) FROM card
WHERE 고객등급 = 'vip' 우선 등급이 'vip'인 사람들의 최대와 최소를 구해서 나눠보니까 35.76이 잘 나오는군요
SELECT max(사용금액), min(사용금액), max(사용금액) / min(사용금액) FROM card
WHERE 고객등급 = '패밀리' 등급이 '패밀리'인 사람들의 최대와 최소를 구해도 30.4가 잘 나오는군요
근데 이렇게 각각 3줄 쓰기 싫으면 GROUP BY 쓰면 한 번에 처리가능합니다.
SELECT 고객등급, max(사용금액), min(사용금액) , max(사용금액)/min(사용금액) FROM card
GROUP BY 고객등급 ORDER BY 고객등급;이러면 같은 고객등급끼리 모아서 통계를 내줄 수 있습니다.
뭐라도 직접 해봐야지 답만 따라적어보고 "음 그렇구나~" 하고 넘어가면 SQL평생 혼자 못짭니다.
'Mysql&DBeaver' 카테고리의 다른 글
| DBeaver)컬럼에 안전하게 제약 (Constraints) 주기 (0) | 2024.09.06 |
|---|---|
| DBeaver)중요한 IF / CASE 문법 (0) | 2024.09.06 |
| DBeaver)SELECT 안에 SELECT 또 쓸 수 있음 (서브쿼리) (0) | 2024.09.06 |
| DBeaver)숫자 조작하는 SQL 함수들 (0) | 2024.09.06 |
| DBeaver)컬럼 출력시 사칙연산 넣기 & 문자다루는 함수 (0) | 2024.09.06 |